日常操作
存储过程的调用
1
2
|
-- 使用 CALL 方式,有入参填入参,出参则填 NULL
CALL TEST.CLOSE_USER_SESSION('入参',NULL,NULL);
|
CALL 调用会返回结果
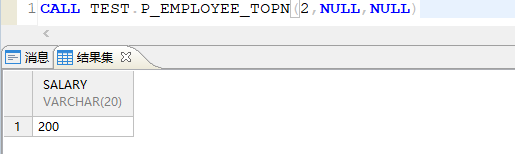
1
|
SELECT TEST.CLOSE_USER_SESSION('入参');
|
用 SELECT 执行,可以返回结果,但是如果有输出参数的话,不能使用这个方式
存储过程的调试与编译
存储过程编译:
点击运行和编译 (F8) 并不会真正执行存储过程,只是编译

存储过程调试:
点击这个乌龟一样的图标
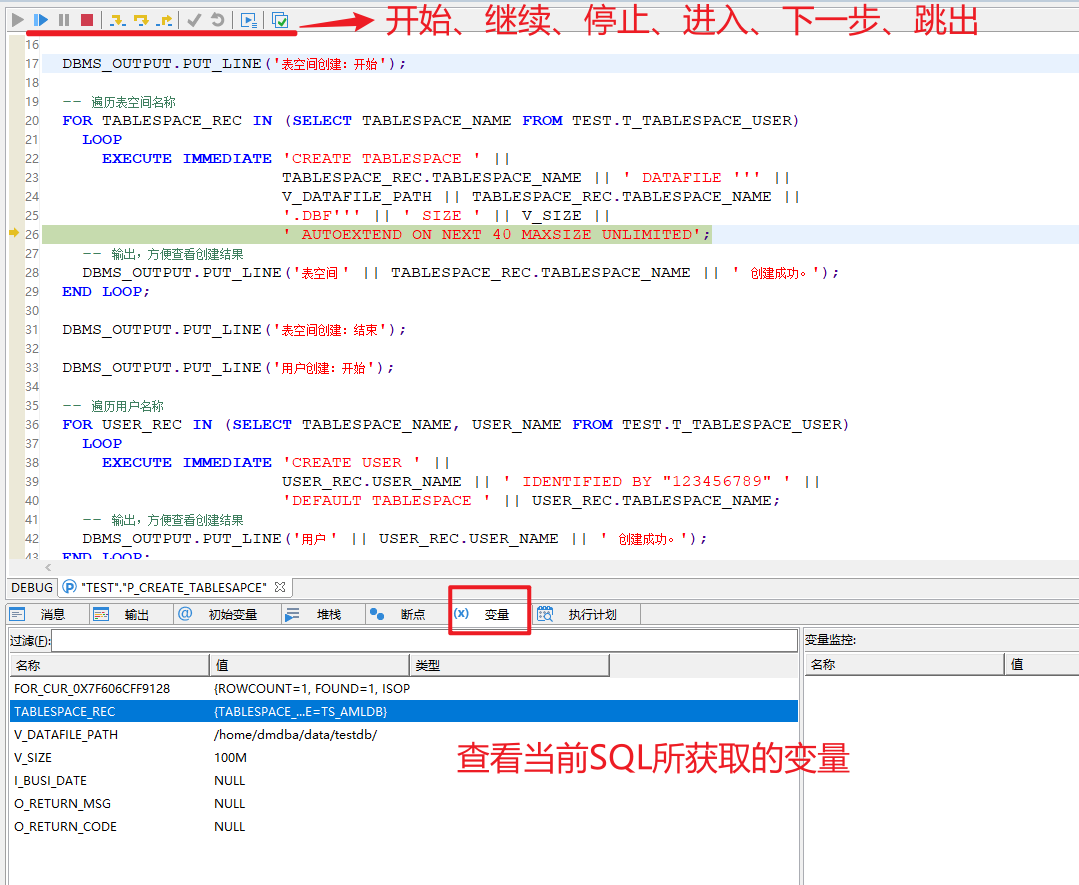
结束后,可能是这样的
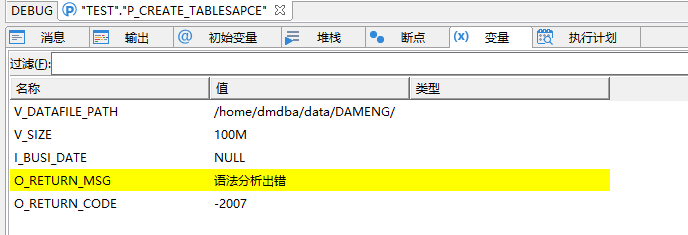
调试完毕记得回滚,另外,如果存储过程中有 COMMIT 会造成事务提交
all_source 字符串截断
1
2
3
4
5
6
7
8
9
|
[执行语句1]:
SELECT *
FROM ALL_SOURCE A
WHERE UPPER(A.TEXT) LIKE '%INSERT%TAAML_N_CUSTOMERINFO_FUND%'
;
执行失败(语句1)
-6108: 字符串截断
1条语句执行失败
|
可以如下查询:
1
2
3
4
5
6
|
-- 使用 regexp_like 正则表达式
-- 注意参数 i 必须是小写,它是不区分大小写匹配
SELECT *
FROM SYS.ALL_SOURCE A
WHERE REGEXP_LIKE(A.TEXT, 'INTO.*?SETT.T_NOR_CLIENT', 'i')
;
|
查询重复数据
在ETL过程中,报错主键冲突(违反唯一约束),都是由于重复数据导致的。重复数据一般分两种情况:
- 表里有一条
ABC 数据,然后又往表里插入一条 ABC 数据,造成主键冲突
- 表里没有数据,ETL过程可能由于表关联条件一对多或者
WHERE 条件没有充分过滤,导致处理出来多条重复数据
一般根据主键来查,根据主键进行 count ,使用 having 筛出 >1
1
2
3
4
5
|
SELECT A.TAACCOUNTID,
COUNT(*)
FROM HSRAW.TAAML_N_CUSTOMERINFO_FUND A
GROUP BY A.TAACCOUNTID
HAVING COUNT(*) > 1
|
如果是多张表关联产生的重复数据,也是根据目标表的主键字段进行 count ,只不过需要将 from 后边的表都关联上
更改表字段数据类型
当表字段需要更改数据类型的时候,通常因为表里该字段已经存在数据了,无法直接修改。
比如 T_FILE_INFO 表里有字段和类型是 FILE_CONTENT VARCHAR2(8000)
当该字段数据超长后,需要它把调整为 CLOB TEXT 大字段类型,如何调整?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
-- 备份该表,保证容错
CREATE TABLE T_FILE_INFO_BAK AS SELECT * FROM T_FILE_INFO;
-- 给表新增大字段
ALTER T_FILE_INFO ADD FILE_CONTENT_NEW CLOB;
COMMENT ON COLUMN T_FILE_INFO.FILE_CONTENT_NEW IS '文件内容';
-- 将 FILE_CONTENT 的数据写入 FILE_CONTENT_NEW
UPDATE T_FILE_INFO SET FILE_CONTENT_NEW = T_FILE_INFO;
-- 把两个字段名互相调整
ALTER T_FILE_INFO RENAME COLUMN FILE_CONTENT TO FILE_CONTENT_OLD;
ALTER T_FILE_INFO RENAME COLUMN FILE_CONTENT_NEW TO FILE_CONTENT;
-- 删除 类型为 VARCHAR2(8000) 的字段 FILE_CONTENT_OLD
ALTER TABLE T_FILE_INFO DROP COLUMN FILE_CONTENT_OLD;
-- 把备份表删掉(有时候没有权限删,正常,留着也行)
DROP TABLE T_FILE_INFO_BAK;
|
创建索引
达梦的大字段类型是不能创建索引的,CLOB TEXT BLOB ,会报错
级联删除
在删除数据库对象的时候(用户、表、存储过程等),可能出现当前对象被占用的报错
使用级联删除
1
|
DROP USER DMUSER_NAME CASCADE;
|
KILL 会话
KILL会话需要DBA 权限的
1
2
3
4
5
|
-- 执行这个KILL
CALL SP_CLOSE_SESSION('SESSION_ID');
-- 可通过 V$SESSIONS 查 会话ID
SELECT * FROM SYS.V$SESSIONS A WHERE A.STATE = 'ACTIVE';
|
普通用户KILL会话的方法
生产环境中,有些项目的用户是不给 DBA 权限的,导致了执行了这么SQL,但是耗时很久形成阻塞,想KILL它,怎么办?
思路:
1.使用 DBA 用户创建存储过程,里边写 KILL 掉自己会话的代码
写法一
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
CREATE OR REPLACE PROCEDURE DBAUSER.CLOSE_USER_SESSION(SESSION_ID BIGINT)
AS
CURR_NAME VARCHAR(32);
SESS_NAME VARCHAR(32);
BEGIN
--校验用户,只能杀自己执行的
SELECT USER INTO CURR_NAME;
SELECT USER_NAME INTO SESS_NAME FROM V$SESSIONS WHERE SESS_ID=SESSION_ID;
IF CURR_NAME = SESS_NAME THEN
SP_CLOSE_SESSION(SESSION_ID);
ELSE
PRINT ' ';
PRINT '执行失败,只能关闭当前用户连接的会话!!!' ;
END IF;
EXCEPTION
WHEN NO_DATA_FOUND THEN
PRINT ' ';
PRINT '执行失败,没有找到对应的会话 !!!';
WHEN OTHERS THEN
PRINT ' ';
PRINT SQLCODE||' '||SQLERRM;
END;
|
写法二
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
CREATE OR REPLACE PROCEDURE CLOSE_USER_SESSION( SESSION_ID IN BIGINT,
O_RETURN_MSG OUT VARCHAR2,
O_RETURN_CODE OUT INTEGER )
IS
--=========================================================================
-- AUTHOR: WQ
-- CREATE_DATE: 20240719
-- VERSION: 1.0
-- MARK: 普通用户 KILL 会话的方式
--=========================================================================
--=========================================================================
-- 业务变量
CURR_NAME VARCHAR(32);
SESS_NAME VARCHAR(32);
--=========================================================================
BEGIN
--校验用户,只能杀自己执行的
SELECT USER INTO CURR_NAME;
SELECT USER_NAME INTO SESS_NAME FROM V$SESSIONS WHERE SESS_ID=SESSION_ID;
-- 当前用户 = V$SESSION里当前会话ID用户
IF CURR_NAME = SESS_NAME THEN
-- 关闭会话
SP_CLOSE_SESSION(SESSION_ID);
ELSE
O_RETURN_CODE := ' ';
O_RETURN_MSG := '执行失败,非当前用户的会话';
END IF;
O_RETURN_CODE := '1';
O_RETURN_MSG := '执行成功';
EXCEPTION
/* -- NO_DATA_FOUND 是达梦自带的预定义异常,为描述数据未找到
WHEN NO_DATA_FOUND THEN
PRINT ' ';
PRINT '执行失败,没有找到对应的会话 !!!';
*/
WHEN OTHERS THEN
O_RETURN_CODE := SQLCODE;
O_RETURN_MSG := SQLERRM;
ROLLBACK;
END;
|
2.把存储过程的执行权限授予普通用户
1
|
GRANT EXECUTE ON DBAUSER.CLOSE_USER_SESSION TO TESTUSER;
|
3.普通用户查询需要 KILL 的会话ID 并 执行存储过程
1
2
3
4
5
|
-- 查询 会话 ID
SELECT * FROM SYS.V$SESSIONS A WHERE A.STATE = 'ACTIVE';
-- 执行存储过程
CALL TEST.CLOSE_USER_SESSION('140052047263656',NULL,NULL);
|
用户权限
package 类型
达梦的 type 类型,是整合到了 package 里,如果需要授权 type,给 package 即可
1
|
GRANT EXECUTE PACKAGE TO USER;
|
修改用户密码
需要使用具有 DBA 角色的用户,可根据上方的SQL语句查询
1
|
ALTER USER SYSDBA IDENTIFIED BY "PASSWORD";
|
disql 使用特殊密码登录
在 Linux 系统里,disql 的使用是:./disql user/passwd@IP:PORT 如果密码中含有特殊字符,比如密码里含有 @ ,需要使用双引号包起来,然后再使用单引号进行转义(Windows使用还是使用刷双引号),例如
1
2
3
4
5
|
# Linux
./disql SYSDBA/'"!@#$12345"'@IP:PORT
# Windows
disql SYSDBA/"""!@#$12345"""
|
当然,用户密码后边的 @IP:PORT 默认缺省本机的IP和5236的。
如果需要实例不同,那么连接就可以具体填写 @ 后边的 IP 和端口,连接到指定的实例
用户解锁
用户输入密码多了,被锁定,解锁:
1
2
3
4
5
6
7
8
9
10
11
|
-- 查看状态
SELECT B.USERNAME,
B.ACCOUNT_STATUS,
A.*
FROM SYS.SYSUSERS A
LEFT JOIN SYS.DBA_USERS B
ON A.ID = B.USER_ID
;
-- 解锁
ALTER USER SYSDBA ACCOUNT UNLOCK;
|
也可以在达梦管理工具 - 用户 - 解锁
查询大字段(CLOB\BLOB)长度
正常字段使用 LENGTH 函数求长度
大字段使用 LENGTHB 函数求长度
1
2
3
|
SELECT ID ,LENGTHB(LISTAGG2(C1,'->') WITHIN GROUP (ORDER BY ID))
FROM TEST.T_LISTAGG_TEST
GROUP BY ID;
|
listagg\listagg2
listagg2 和 listagg 是一样的用法,都是将多行合并成一行,如上
只不过 listagg 返回的是 VARCHAR 类型,listagg2 返回的是 CLOB 类型
1
2
|
LISTAGG(COL_A, ',') WITHIN GROUP(ORDER BY COL_B)
-- ',' 表示使用逗号做分隔符
|
listagg 报字符串截断
因为 listagg 返回的是 VARCHAR 类型,字节有长度限制,所以就报字符串截断
使用 listagg2 让它返回大字段 CLOB 类型,就可以查了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
--创建测试表TEST
CREATE TABLE TEST.T_LISTAGG_TEST
AS SELECT LEVEL ID ,RPAD('A',1000,'B') C1 FROM DUAL CONNECT BY LEVEL<=10;
--插入测试数据
BEGIN
FOR I IN 1..10
LOOP
INSERT INTO TEST.T_LISTAGG_TEST
SELECT * FROM TEST.T_LISTAGG_TEST;
END LOOP;
COMMIT;
END;
--查询测试表的总数据量
SELECT COUNT(*) FROM TEST.T_LISTAGG_TEST;--10240
-- 可查
SELECT ID, LISTAGG2(C1,'->') WITHIN GROUP (ORDER BY ID)
FROM TEST.T_LISTAGG_TEST
GROUP BY ID;
|
备份表
备份表通常使用 AS LIKE 去创建
1
2
3
4
5
|
-- AS 方法备份结构 + 数据
CREATE TABLE TEST.T_TEST_BAK AS SELECT * FROM TEST.T_TEST;
-- LIKE 方法备份结构
CREATE TABLE TEST.T_TEST_BAK LIKE TEST.T_TEST;
|
但是这两种方式是无法备份原表的主键、约束,需要备份主键、约束需手动根据原表的建表语句,修改之后执行。
动态调整归档文件
新版的达梦支持在线动态修改归档文件
1
2
3
4
5
|
SELECT * FROM SYS.V$VERSION;
DM Database Server 64 V8
DB Version: 0x7000c
03134284058-20240205-217834-20046
|
反正这个版本是支持的,DM8的应该都支持
注意:集群的情况下,主库和备库,都需要手动执行这个 SQL 代码,来调整。备库为 Standby 模式也可以执行。
动态调整归档文件上限
1
|
ALTER DATABASE MODIFY ARCHIVELOG 'DEST=/u01/dmdata/zgfxq/arch, TYPE=LOCAL, FILE_SIZE=128, SPACE_LIMIT=81920';
|
给归档文件加个 ARCH_RESERVE_TIME 参数,该参数是调整归档保留时间(单位:分钟),通常保留 7 天归档文件
1
|
ALTER DATABASE MODIFY ARCHIVELOG 'DEST=/u01/dmdata/zgfxq/arch, TYPE=LOCAL, FILE_SIZE=128, SPACE_LIMIT=81920 ARCH_RESERVE_TIME=10080'
|
只有是归档文件里支持的,都可以修改
查看达梦执行SQL记录
1
2
3
4
5
6
7
8
9
10
11
12
|
SELECT A.CURR_SCH,
A.USER_NAME,
A.CREATE_TIME,
A.CLNT_IP,
A.APPNAME,
A.OSNAME,
A.SESS_ID,
A.SQL_TEXT,
DATEDIFF(SS, LAST_RECV_TIME, SYSDATE()) AS EXETIME,
SF_GET_SESSION_SQL(A.SESS_ID) AS FULLSQL
FROM V$SESSIONS A
ORDER BY A.CREATE_TIME ;
|
达梦系统表查询
对象、角色
查数据库对象
1
|
SELECT * FROM ALL_OBJECTS;
|
查数据库对象的内容
1
|
SELECT * FROM ALL_SOURCE;
|
查数据库角色
1
|
SELECT * FROM DBA_ROLES;
|
查数据库用户所拥有的角色
1
|
SELECT * FROM DBA_ROLE_PRIVS;
|
查数据库用户
1
|
SELECT * FROM DBA_USERS;
|
查数据库用户密码
1
|
SELECT * FROM SYSUSERS;
|
查看用户的系统权限
1
|
SELECT * FROM DBA_SYS_PRIVS;
|
查看用户的对象权限
1
|
SELECT * FROM DBA_TAB_PRIVS;
|
表字段
1
|
SELECT * FROM DBA_TAB_COLUMNS;
|
表空间
查表空间大小
1
2
3
|
SELECT NAME AS TABLEPACE_NAME,
TOTAL_SIZE * SF_GET_PAGE_SIZE()/1024/1024||'M' AS TS_SIZE
FROM V$TABLESPACE;
|
查表空间物理文件路径、大小
1
2
3
4
5
6
7
|
SELECT T.NAME TABLESPACE_NAME,
T.ID FILE_ID,
D.PATH FILE_NAME,
D.TOTAL_SIZE*SF_GET_PAGE_SIZE()/1024/1024||'M' TOTAL_SPACE
FROM V$TABLESPACE T,
V$DATAFILE D
WHERE T.ID=D.GROUP_ID;
|
也可以在达梦管理工具 - 表空间 查询
查表空间使用率
1
2
3
4
5
6
7
|
SELECT T1.NAME TABLESPACE_NAME,
T2.FREE_SIZE*SF_GET_PAGE_SIZE()/1024/1024||'M' FREE_SPACE,
T2.TOTAL_SIZE*SF_GET_PAGE_SIZE()/1024/1024||'M' TOTAL_SPACE,
T2.FREE_SIZE*100/T2.TOTAL_SIZE "% FREE"
FROM V$TABLESPACE T1,
V$DATAFILE T2
WHERE T1.ID=T2.GROUP_ID;
|
查大小写敏感
1
2
3
|
SELECT CASE_SENSITIVE();
-- 0 不敏感
-- 1 敏感
|
查字符集
1
2
3
4
5
6
7
8
|
SELECT unicode();
-- 或者
SELECT (CASE SF_GET_UNICODE_FLAG()
WHEN '0' THEN 'GBK18030'
WHEN '1' THEN 'UTF-8'
WHEN '2' THEN 'EUC-KR'
END);
|
查达梦报错返回的状态码
1
|
SELECT * FROM V$ERR_INFO;
|
查数据库实例的初始化参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
SELECT '实例名称' 数据库选项,INSTANCE_NAME 数据库集群相关参数值 FROM V$INSTANCE
UNION ALL
SELECT TOP 1 '数据库版本', BANNER ||'.'||ID_CODE FROM V$VERSION
UNION ALL
SELECT '字符集',
CASE SF_GET_UNICODE_FLAG() WHEN '0' THEN 'GBK18030' WHEN '1' THEN 'UTF-8' WHEN '2' THEN 'EUC-KR' END
UNION ALL
SELECT '页大小',CAST(PAGE()/1024 AS VARCHAR)
UNION ALL
SELECT '簇大小',CAST(SF_GET_EXTENT_SIZE() AS VARCHAR)
UNION ALL
SELECT '大小写敏感',CAST(SF_GET_CASE_SENSITIVE_FLAG() AS VARCHAR)
UNION ALL
SELECT '数据库模式',MODE$ FROM V$INSTANCE;
|
其实这个用达梦管理工具右键数据库实例,选择【管理服务器】就行
查询存储过程的依赖关系
注意
NAME =‘HSFUND’ 改为需要查询的用户名
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
SELECT *
FROM ( SELECT DOBJS.SCHEMA_NAME "模式名",
DOBJS.NAME "对象名称",
SOBJS.NAME "被依赖对象所属模式",
DOBJS.REFED_TYPE$ "被依赖对象类型",
OBJS.NAME "被依赖对象名",
TEXTS.TXT "对象定义"
FROM (SELECT OBJPROC.NAME,
OBJPROC.SCHEMA_NAME,
SDEP.REFED_TYPE$,
SDEP.REFED_ID
FROM SYSDEPENDENCIES SDEP
INNER JOIN (SELECT
/*+ OPTIMIZER_OR_NBEXP(2) ORDER(PROC_OBJ_INNER, SCH_OBJ_INNER, USER_OBJ_INNER)*/
PROC_OBJ.ID,
PROC_OBJ.NAME,
SCH_OBJ.NAME "SCHEMA_NAME"
FROM (SELECT ID,
NAME
FROM SYSOBJECTS
WHERE TYPE$='SCH'
AND ID = (SELECT ID FROM SYSOBJECTS WHERE TYPE$='SCH' AND NAME ='HSFUND')) SCH_OBJ, (SELECT PROC_OBJ_INNER.ID,
PROC_OBJ_INNER.NAME,
PROC_OBJ_INNER.CRTDATE,
PROC_OBJ_INNER.INFO1,
PROC_OBJ_INNER.SCHID,
PROC_OBJ_INNER.VALID
FROM SYSOBJECTS PROC_OBJ_INNER,
SYSOBJECTS SCH_OBJ_INNER,
SYSOBJECTS USER_OBJ_INNER
WHERE PROC_OBJ_INNER.SUBTYPE$='PROC'
AND PROC_OBJ_INNER.TYPE$='SCHOBJ'
AND PROC_OBJ_INNER.INFO1&0X01 = 0X01
AND (PROC_OBJ_INNER.INFO1/4)
&0X01=0
AND PROC_OBJ_INNER.SCHID = (SELECT ID FROM SYSOBJECTS WHERE TYPE$='SCH' AND NAME ='HSFUND')
AND USER_OBJ_INNER.SUBTYPE$ = 'USER'
AND SCH_OBJ_INNER.ID = PROC_OBJ_INNER.SCHID
AND SCH_OBJ_INNER.PID = USER_OBJ_INNER.ID
AND SF_CHECK_PRIV_OPT(UID(), CURRENT_USERTYPE(), PROC_OBJ_INNER.ID, USER_OBJ_INNER.ID, USER_OBJ_INNER.INFO1, PROC_OBJ_INNER.ID) = 1) PROC_OBJ
WHERE PROC_OBJ.SCHID=SCH_OBJ.ID
ORDER BY PROC_OBJ.NAME) OBJPROC
ON SDEP.ID=OBJPROC.ID) DOBJS
LEFT JOIN SYSOBJECTS OBJS
ON DOBJS.REFED_ID = OBJS.ID
LEFT JOIN SYSOBJECTS SOBJS
ON OBJS.SCHID = SOBJS.ID
AND OBJS.SCHID != 0
LEFT JOIN SYSTEXTS TEXTS
ON OBJS.ID = TEXTS.ID ) T
WHERE T."对象名称" = 'P_ACCOHOLDERINFO_FUND'; -- 注释 WHERE 就是查询所有的
|
查询系统内置函数
监控查询语句汇总
慢SQL查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
--检查当前数据库中包含的慢 SQL 及阻塞语句
SELECT
DS.SESS_ID "被阻塞的会话ID",
DS.SQL_TEXT "被阻塞的SQL",
DS.TRX_ID "被阻塞的事务ID",
(CASE L.LTYPE WHEN 'OBJECT' THEN '对象锁' WHEN 'TID' THEN '事务锁' END CASE ) "被阻塞的锁类型",
DS.CREATE_TIME "开始阻塞时间",
SS.SESS_ID "占用锁的会话ID",
SS.SQL_TEXT "占用锁的SQL",
SS.CLNT_IP "占用锁的IP",
L.TID "占用锁的事务ID"
FROM
V$LOCK L
LEFT JOIN V$SESSIONS DS
ON
DS.TRX_ID = L.TRX_ID
LEFT JOIN V$SESSIONS SS
ON
SS.TRX_ID = L.TID
WHERE
L.BLOCKED = 1
|
未提交事务查询
1
2
3
4
5
6
7
8
9
|
SELECT B.OBJECT_NAME,
C.SESS_ID,
A.*
FROM V$LOCK A,
DBA_OBJECTS B,
V$SESSIONS C
WHERE A.TABLE_ID = B.OBJECT_ID
AND LTYPE = 'OBJECT'
AND A.TRX_ID = C.TRX_ID;
|
事务进度查询
当存在活动事务时,可以查询事务当前进度(执行时间、插入行数、删除行数、更新行数、是否正在回滚)便于判断事务当前状态
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
SELECT DATEDIFF(SS,LAST_RECV_TIME,SYSDATE) SS,
S.LAST_RECV_TIME,
S.SESS_ID,
T.THRD_ID,
T.ID,
S.SQL_TEXT,
SF_GET_SESSION_SQL(S.SESS_ID) AS SQL_FULL_TEXT,
T.STATUS,
T.INS_CNT,
T.DEL_CNT,
T.UPD_CNT,
T.UPD_INS_CNT,
T.WAITING,
T.START_LSN,
T.ROLLBACK_FLAG,
T.LOCK_CNT,
S.AUTO_CMT,
S.CONNECTED,
S.CLNT_IP,
S.USER_NAME
FROM V$SESSIONS S,V$TRX T
WHERE S.TRX_ID=T.ID
AND S.STATE='ACTIVE'
AND S.SESS_ID<>SESSID;
|
查看已使用 Roll 表空间
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
select
a.tablespace_name space_name ,
total /1024/1024/1024 "总大小(G)" ,
free /1024/1024/1024 "可使用(G)" ,
(total -free) /1024/1024/1024 "已使用(G)",
round((total -free)/total, 4)*100 "使用率"
from
(
select
tablespace_name,
sum(bytes) free
from
dba_free_space
group by
tablespace_name
)
a,
(
select
tablespace_name,
sum(bytes) total
from
dba_data_files
group by
tablespace_name
)
b
where
a.tablespace_name = b.tablespace_name
ORDER BY
"使用率" DESC;
|
达梦 dm.ini 参数方面
初始化实例后不可修改的参数
就是初始化实例后,想要修改,必须重新初始化实例
LENGTH_IN_CHAR
长度是否以字符为单位,默认为 0-否
页大小 PAGE_SIZE
生产上一般会建议 32KB (实在不行至少得 16KB )
页大小最直观的影响,就是字段类型 VARCHAR2 ,16KB 及以上时最大长度为 8000
簇大小 EXTENT_SIZE
生产上一般会建议 32KB (实在不行至少得 16KB )
大小写敏感 CASE_SENSITIVE
默认敏感 0 ,一般如果从 oracle 移植过来的,设置为大小写不敏感 1
该参数开发、测试、生产环境保持一致
1
|
SELECT CASE_SENSITIVE(); -- 1
|
大小写敏感
- 查询、创建表时,不加
"" ,则表名、列名自动转为大写
- 创建表:“DMTABLE” 与 “dmtable” ,那么它们是两张表,一张是大写名称,一张是小写名称
- 列名:“COLUMN” 与 “column” 与 “coLumn” 都是不同的字段
- 查询 A 返回 A,不会返回 a
大小写不敏感
则跟oracle一样操作,查A返回A \ a
表名:DMTABLE 与 dmtable 是一张表
列名:COLUMN 与 column 是一个字段
字符集 CHARSET
默认为 0-GB18030
也可以改为 1-UTF8
主要是看项目,该参数开发、测试、生产环境保持一致
初始化实例后可修改的参数
COMPATIBLE_MODE
Oracle 没有空串这个概念,所以 "" 和 null 都是显示 null
达梦里边不行,达梦里边 "" 是 "" ,NULL 是 NULL ,两个不一样
参数里设置
即可将 "" 与 NULL 等价,静态参数,修改后重启生效
这个也是兼容 ORACLE 语法的参数
MAX_SESSION
该参数是达梦最大会话连接数量,一般设置大一点,5000-10000
不然可能会报错:reached the max session limit
dm.ini 里设置,或者 sql 设置
1
|
SP_SET_PARA_VALUE(2,'MAX_SESSIONS', 5000);
|
这个默认是 10000
CASE_COMPATIBLE_MODE
CASE 转换数据类型的兼容参数,默认兼容 1
0:不兼容;
1:兼容,本模式下,当函数 DECODE() 中的多个CASE 类型不一致时,DECODE 会从其中选择一
个类型进行匹配;
2:兼容,本模式下,当函数 DECODE() 中的多个CASE 类型不一致时,DECODE 根据第一个 CASE
的类型来决定匹配类型。
CALC_AS_DECIMAL
达梦默认的除法,是会丢弃掉小数的,只保留整数部分。需要修改参数,或者直接修改 dm.ini 里的参数为 1
1
|
SP_SET_PARA_VALUE(2,'CALC_AS_DECIMAL',1);
|
修改后重启数据库服务
PK_WITH_CLUSTER
1
|
[-3243]: 同时包含聚集 KEY 和大字段
|
该参数默认为1 ,出现此错误时,把这个参数修改为 0
1
|
SP_SET_PARA_VALUE(1,'PK_WITH_CLUSTER',0);
|
该参数与建表时的主键索引有关,达梦数据库在创建表时,如果创建主键,则默认主键是聚簇索引键。如果没有主键,则默认rowid 作为聚簇索引键
修改实例名
直接修改 dm.ini 里的配置文件就好了,注意主备都修改,修改后重启数据库服务
达梦数据类型方面
这里其实也是信创项目改造、迁移过程中的一个可能遇到的地方
不能去重的数据类型
clob/blob/text 大字段的数据类型不能去重
DATE \ DATETIME 类型被自动转换为 TIMESTAMP 类型
在达梦 dm.ini 中设置了 COMPATIBLE_MODE = 2 兼容 ORACLE,然后创建表的时候:
1
2
3
4
5
6
|
DROP TABLE IF EXISTS TEST.T_WEATHER;
CREATE TABLE TEST.T_WEATHER(
ID INT,
RECORDDATE DATE,
TEMPERATURE INT
);
|
注意这里的数据类型 DATE ,创建后数据类型被转换为 TIMESTAMP ,这个会导致:
所以在解决的迁移、改造过程中,源表结构不动,可以对这个数据类型使用进行处理
原来的处理逻辑使用 DATEDIFF 时间差函数,改为使用 TRUNC 函数处理
1
2
3
4
5
6
7
8
9
10
11
12
13
|
SELECT T.*
FROM (
SELECT A.ID,
A.RECORDDATE,
A.TEMPERATURE,
LEAD(A.RECORDDATE, 1, NULL) OVER(ORDER BY A.RECORDDATE) AS DD,
LEAD(A.TEMPERATURE, 1, NULL) OVER(ORDER BY A.RECORDDATE) AS WD
FROM TEST.T_WEATHER A
) T
WHERE T.WD > T.TEMPERATURE
AND TRUNC(T.DD) - TRUNC(T.RECORDDATE) = 1
-- AND DATEDIFF(T.DD, T.RECORDDATE) = 1
;
|
INT 被转换为 INTEGER ,不过这个没有关系
性能优化方面
跟踪日志
达梦的跟踪日志是以 dmsql_数据库实例名.log 类型命名的文件
跟踪日志内容包含系统各会话执行的 SQL 语句、参数信息、错误信息等。跟踪日志主要用于分析错误和分析性能问题,比如,可以挑出系统现在执行速度较慢的 SQL 语句,进而对其进行优化。
打开跟踪日志对系统的性能有较大影响,一般用于查错和调优的时候才会打开,默认情况下系统是关闭跟踪日志的。
dm.ini 中 SVR_LOG = 1 是打开,也可以这样:
1
|
SP_SET_PARA_VALUE(0, 'SVR_LOG', 1);
|
然后执行SQL,待跟踪日志记录后,再关掉:
1
|
SP_SET_PARA_VALUE(1, 'SVR_LOG', 0);
|
dm.key 方面
不重启数据库更换dm.key
到数据库安装目录 bin 下将临时授权 dm.key 重命名
把正式的 dmxxxx.key 修改为 dm.key 并拷贝到 bin 目录下
1
|
mv dmxxxx.key /home/dmdbms/bin/dm.key
|
然后到达梦客户端执行SQL
日志报错方面
cmd 13 validate error
在用了 shell 脚本巡检达梦的日志后,发现实例日志里产生报错:
1
|
2024-07-25 14:19:41.897 [ERROR] database P0002834456 T0000000000003001151 cmd 13 validate error!
|
在达梦社区里搜索该报错,找到了相关内容:
应用使用连接达梦数据库的JDBC驱动有问题
可以使用达梦安装路径下的自带的驱动器 ../drivers/jdbc
(后边咨询达梦技术支持人员,确实与 JDBC 驱动有关,应用使用的 JDBC 驱动版本与数据库驱动版本差异较大造成,驱动版本差异较大会影响性能)
附:查询活动会话驱动信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
SELECT * FROM (
SELECT SESS_ID,
CURR_SCH,
USER_NAME,
DATEDIFF(SS,LAST_RECV_TIME,SYSDATE) Y_EXETIME,
APPNAME,
CLNT_IP,
CREATE_TIME,
CLNT_TYPE,
CLNT_VER,
STATE
FROM V$SESSIONS
)
WHERE 1=1 --Y_EXETIME>=2
ORDER BY Y_EXETIME;
|
signal 信号
新增了一个实例,在检查实例日志时,发现报错:
1
2
3
|
2024-09-03 09:32:43.847 [FATAL] database P0002168637 T0000000000002168637 sigterm_handler receive signal 2
2024-09-03 10:16:43.830 [FATAL] database P0002170305 T0000000000002170305 sigterm_handler receive signal 15
2024-09-04 14:52:00.343 [FATAL] database P0002175684 T0000000000002175684 sigterm_handler receive signal 15
|
这个其实是 Linux 的 signal 信号:
2 应该是我手动终止的
15 应该是应用或者达梦管理工具传来的终止信号?
Linux Signal 信号大全
| SIGHUP |
1 |
终止进程 |
终端线路挂断 |
|
| SIGINT |
2 |
终止进程 |
中断进程 |
Ctrl+C |
| SIGQUIT |
3 |
建立CORE文件终止进程,并且生成core文件 |
Ctrl+\ |
|
| SIGILL |
4 |
建立CORE文件,非法指令 |
|
|
| SIGTRAP |
5 |
建立CORE文件,跟踪自陷 |
|
|
| SIGABRT |
6 |
|
|
|
| SIGIOT |
6 |
建立CORE文件,执行I/O自陷 |
|
|
| SIGBUS |
7 |
建立CORE文件,总线错误 |
|
|
| SIGFPE |
8 |
建立CORE文件,浮点异常 |
|
|
| SIGKILL |
9 |
终止进程 |
杀死进程 |
|
| SIGUSR1 |
10 |
终止进程 |
用户定义信号1 |
|
| SIGSEGV |
11 |
建立CORE文件,段非法错误 |
|
|
| SIGUSR2 |
12 |
终止进程 |
用户定义信号2 |
|
| SIGPIPE |
13 |
终止进程 |
向一个没有读进程的管道写数据 |
|
| SIGALARM |
14 |
终止进程 |
计时器到时 |
|
| SIGTERM |
15 |
终止进程 |
软件终止信号 |
|
| SIGSTKFLT |
16 |
|
|
|
| SIGCLD |
SIGCHLD |
|
|
|
| SIGCHLD |
17 |
忽略信号 |
当子进程停止或退出时通知父进程 |
|
| SIGCONT |
18 |
忽略信号 |
继续执行一个停止的进程 |
|
| SIGSTOP |
19 |
停止进程 |
非终端来的停止信号 |
|
| SIGTSTP |
20 |
停止进程 |
终端来的停止信号 |
Ctrl+Z |
| SIGTTIN |
21 |
停止进程 |
后台进程读终端 |
|
| SIGTTOU |
22 |
停止进程 |
后台进程写终端 |
|
| SIGURG |
23 |
忽略信号 |
I/O紧急信号 |
|
| SIGXCPU |
24 |
终止进程 |
CPU时限超时 |
|
| SIGXFSZ |
25 |
终止进程 |
文件长度过长 |
|
| SIGVTALRM |
26 |
终止进程 |
虚拟计时器到时 |
|
| SIGPROF |
27 |
终止进程 |
统计分布图用计时器到时 |
|
| SIGWINCH |
28 |
忽略信号 |
窗口大小发生变化 |
|
| SIGPOLL |
SIGIO |
|
|
|
| SIGIO |
29 |
忽略信号 |
描述符上可以进行I/O |
|
| SIGPWR |
30 |
|
|
|
| SIGSYS |
31 |
|
|
|
| SIGUNUSED |
31 |
|
|
|