最近异常交易的项目中,使用到了kafka ,用来实时推送实时成交、委托流水、组合持仓、行情等等数据到自研的平台上做数据监控。那么我这边需要做的内容:将上游的数据直接推送到kafka上,给下游的应用消费kafka数据。这个过程中也遇到了一些问题,因为也是第一次接触kafka ,平且是在实际的项目中使用的,这里经验对我来说还是很宝贵的,所以在这里做一个基础知识、项目中遇到的问题、对应的解决方案的记录。在项目上主要是使用kafka 读取数据,做一个流式处理,供下游应用使用数据。
kafka 主要组件
broker 服务器
kafka集群的服务器,一台服务器就是一个 broker 。
producer 生产者
producer 主要是用于生产消息,是 kafka 当中的消息生产者,生产的消息通过 topic 进行归类,保存到 kafka 的 broker 里面去。
项目上我们的数据平台就是作为一个生产者,通过将上游数据推送到topic里。
topic 主题
kafka 将消息(数据)以 topic 为单位进行归类。在项目里边,一张表推到一个 topic ,需要推几张表就是建几个 topic 。
partition 分区
kafka 里,一个 topic 是可以有多个分区。比如说创建一个有 3 个分区的 topic ,那么整个 topic 的数据都存放在这 3 个分区内(就是说每个分区都存放一部分 topic 的数据)。
consumer 消费者
消费者主要就是消费 kafka topic 里的数据
consumer group 消费者
消费者组里可以有多个消费者,同一个组里的消费者,对于同一条数据,只能消费 1 次。
比如:一个消费者组里有 A 和 B 两个消费者,A 消费了 topic 里的第一条数据,那么 B 就无法消费该 topic 里的第一条数据,因为已经被消费过了。
但是不同的消费者组,还是可以共同消费某个 topic 里的数据的。
消费者组与分区的关系
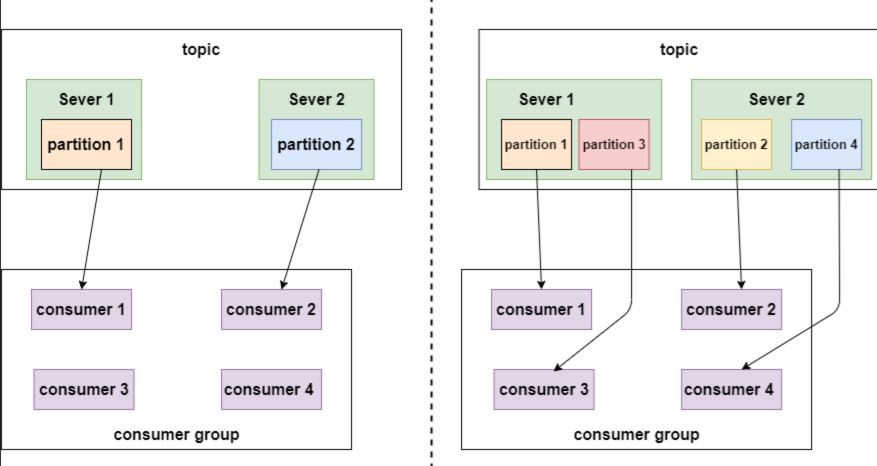
如果 topic 只有 2 个分区,消费者组里有 4 个消费者,那么也只能供 2 个消费者消费。
如果 topic 有 4 个分区,消费者组里的 4 个消费者都能消费数据,并发量就上来了。
所以 topic 里的分区越多,消费的并发越高,处理速度也越快。
partition replicas 分区副本
每个分区的副本,用来控制数据保存在几个 broker 服务器上,通常是几台 broker 就设置几个副本。
segment 文件
一个 partition 分区中由多个 segment 文件组成的。每个 segment 文件又包含了 .log 文件和.index 文件,.log 文件是存放推送的数据,.index 文件存放数据的索引值,用来加快数据的查询速度的。
.index 文件里存的索引值,是与.log文件里的数据位置是对应的。
|
|
.log 文件里会记录offset 偏移量,用于标记消费者读取消息的位置。
kafka 基础操作
kafka启停
kafka 与 zookeeper 强依赖,启动 kafka 之前必须先启动 zookeeper ,否则会报错的
|
|
创建 topic
|
|
删除 topic
|
|
增加 topic partition
|
|
查看 topic 数据
|
|
查询 topic 列表
|
|
kafka 相关问题及解决方案
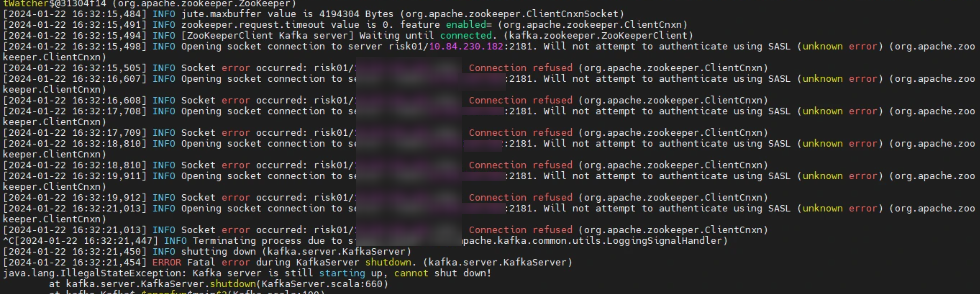
报错 Error while fetching metadata with correlation id
这个报错是在 kafka 查看 topic 里的数据时,出现的错误。查了下资料,它是无法识别到 hostname 导致。
解决方案:
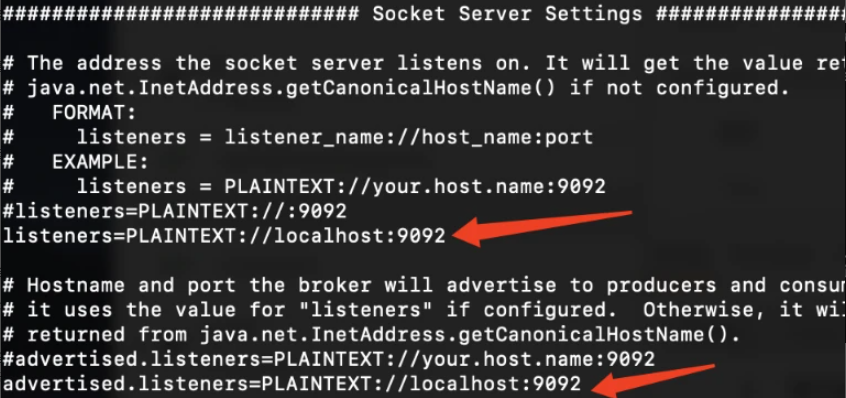
修改 server.properties 配置文件,增加 listeners 。默认的配置是没有这两行的,手动加上。
报错 exiting abnormally
这个是在启动 zookeeper 的时候出现,报错如下图所示:
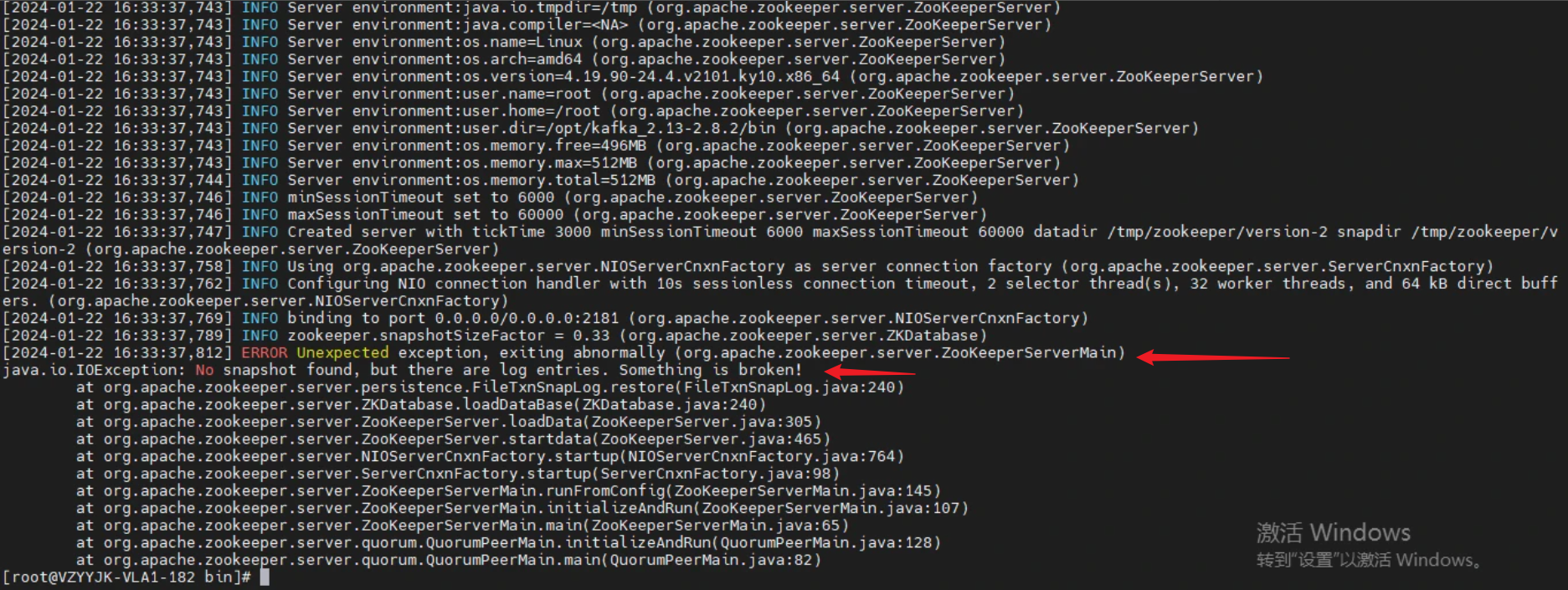
解决方案:
在zookeeper.properties配置文件中,有个 dataDir=/path ,把 /path 路径下的version-2 文件夹删掉,然后重新启动即可。
报错 during kafkaserver startup
启动 kafka 的时候出现,报错如下图所示:
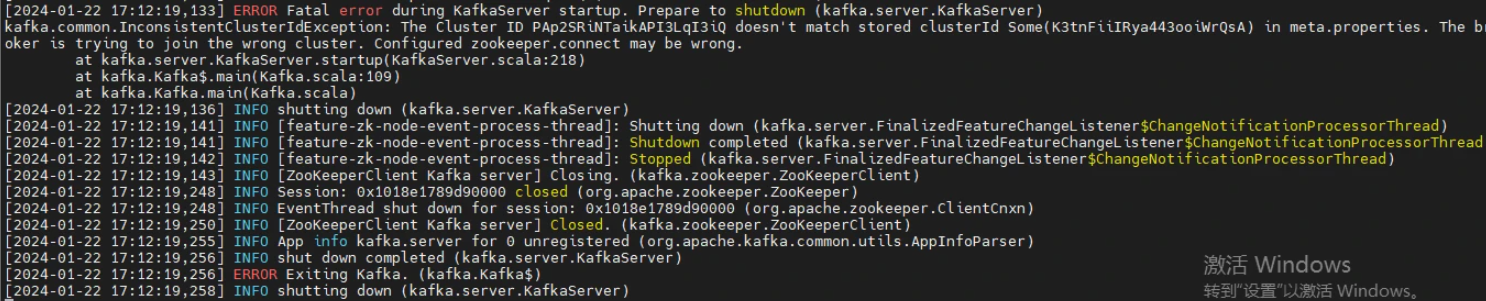
注意这个:

由于启动的 id 和 meta.properties 里边的 id 不一致导致报错。通常是因为关闭 kafka 的时候出现了异常(虽然不知道有什么异常)
解决方案:
|
|
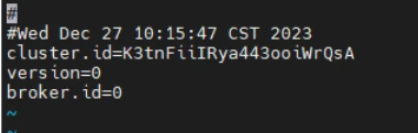
修改为报错里出现的那个括号里的一串id即可。
新增消费者组时数据显示不一致
在做迁移的时候,为了对比迁移前后的数据量是否一致。在迁移后的环境中新增一个消费者组 B,用来消费同一个 topic 数据,发现跟迁移前的消费者组 A 的数据不一致。
消费者组A的数据是当天的数据,但是消费者组B的数据却是几天前的。为啥?
kafka每个消费者组都是独立消费数据,只要是消费同一个 topic,那么数据肯定是一致的。由于一般 kafka 的配置是保留 7 天的数据,所以在新增的消费者组消费同一个 topic 时,它会重头开始消费,即从所以就出现了,消费者组B里是几天前的数据,这是无可避免的。
配置流水字段
由于当时第一次配置的时候,没有配置流水字段,导致了推送数据到 kafka topic 的任务,每次实时推送全量数据过去,导致了数据平台每次启动推送 kafka 的任务,就会迅速占满服务器内存,然后应用挂掉。
后边加入流水字段,将任务配置为增量推送,内存占比就好了很多。
通常是用线性递增的字段,作为流水字段。比如,实时成交表里有成交时间,委托流水表里有委托时间。
配置主键
通过配置主键用来去重,避免推送重复数据到 topic 里。比如:实时成交表里的成交编号,委托流水表里的委托编号,编号是唯一的,那么可以使用编号作为主键。