前言
在做交付工作的时候,环境的搭建也是工作的一个重要环节。公司现在一个产品的架构:B/S架构,采用的技术路基本是低代码平台 + JAVA后端:低代码平台里使用 javascrpit 做功能页面的开发,对于JAVA类也只是调用;业务逻辑都写在数据库的存储过程中。
那运行产品的环境的搭建就主要包括:WEB服务的部署、数据库的部署。当然也有其他的服务,但其他服务需要根据产品的需要进行部署的。我主要负责信创类项目的实施部署,都是在LINUX服务器上部署。
一个环境搭建的思路:
前期环境的准备 » 数据库部署 » 中间件与应用部署 » ETL工具部署
本文总结前期环境的准备
信创项目知识
信创类产品的实施部署从 0 到 1 ,实施部署前期需要了解什么,作为跟客户沟通的技术知识保障。
信创软硬件
数据库:达梦 中间件:东方通、宝兰德 服务器操作系统:麒麟、统信 硬件平台:飞腾、华为、龙芯、海光、鲲鹏…… 内核:AMD、ARM
确认服务器架构信息
信创,产品的框架与数据平台均做了适配,都需要根据内核来确认使用哪个版本。
|
|
确认服务器内存信息
JAVA服务端通常需要设置服务的 JVM ,生产环境通常推荐 JVM > 16G
开发环境、测试环境 JVM 减半作为参考即可
比如:在部署中间件、宝兰德中间件的时候,默认的 JVM 都是 2G,测试服务器只有8G内存的情况下,中间件的JVM修改为4G。
确认数据库参数
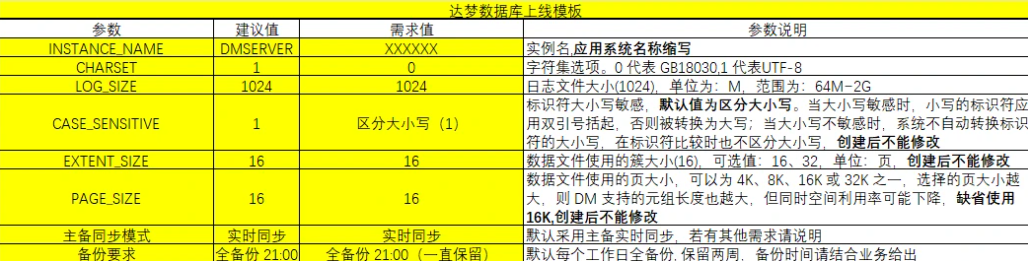
我所遇到的信创项目种,数据库通常使用达梦数据库。达梦数据库,有几个参数是在初始化实例的时候就需要确定的,且初始化实例后无法进行修改,除非重新初始化实例:
- 页大小 (page_size)
- 簇大小 (extent_size)
- 大小写敏感 (case_sensitive)
- 字符集 (charset)
下表为这几个参数的具体含义:
| 名称 | 含义 | 可设置值 |
|---|---|---|
| page_size | 数据文件使用的页大小 | 4/8/16/32 |
| extent_size | 簇大小,每次分配新的段空间时连续的页面 | 16/32/64 |
| case_sensitive | 标识符大小写敏感。当大小写敏感时,小写的标识符要用双引号括起,否则被转换为大写;当大小写不敏感时,系统不自动转换标识符的大小写,在标识符比较时也不区分大小写。默认 Y (1)敏感 | Y/N(1/0) |
| charset | 字符集选项,0:GB18030;1:UTF-8(默认0) | 0/1 |
| length_in_char | VARCHAR类型长度是否以字符为单位(默认为N 0 ) | Y/N(1/0) |
页大小与字段长度有关,簇大小与表空间有关,但是这两个都与我们没有关系,我们需要注意的只有 2 个:
- 大小写敏感
- 字符集编码
产品多为oracle开发,从oracle移植过来,为了更好的兼容,通常开启大小写敏感;字符集编码是GB18030还是UTF-8没关系,但是开发环境、测试环境、生产环境需要字符集编码一致。
在实际的项目实施部署中,客户的开发环境、测试环境通常由我们厂商维护,只有生产环境是由DBA维护。所以在前期的沟通中,我们需要跟DBA确认好达梦数据库里的上述参数,确保开发环境、测试环境、生产环境保持一致。
总结了一份模板如下,页大小和簇大小根据在生产上通常建议设置为32
参数带来的影响
1)编码不一致
当开发环境或者测试环境,与生产环境的字符集编码不一致时,可能会产生字符串长度相关的报错。
比如:
测试环境上是 GB18030 编码,但是生产环境上是 UTF8 编码,因为 GB 编码存一个中文需要的 1 个字节少于 UTF8 存一个中文需要的 3 个字节,测试后的产品功能上了生产环境可能会报出字符串截断的错误。
2)大小写敏感不一致
大小写敏感:查数据内容时,查 a 就是 a,查 A 就是 A
大小写不敏感:查数据内容时,查 a 返回 A、a
如果不设置大小写敏感,不仅是在写查询SQL的时候会影响,在创建对象、写存储过程时,对象名称、字段名称也会受到影响。比如:
|
|
其他可能需要修改的参数
此处的参数指,达梦数据库 dm.ini 配置文件里的参数。在开发环境、测试环境可由自己根据实际情况更改,在生产上必须与DBA沟通后进行更改,也需要保持三个环境中参数的一致性。
dm.ini 配置文件中,有静态参数、动态参数。静态参数需要重启数据库服务后才生效,在生产上重启数据库是一件严肃的事情,需要修改的参数需要自己做好验证是否能够解决实际的情况。
1)COMPATIBLE_MODE
该参数用于控制达梦数据库在部分功能处理时与其他数据库的兼容模式。常用设置:
- 0 - 不兼容
- 1 - 兼容SQL92标准
- 2 - 兼容ORACLE
- 3 - 兼容SQL SERVER
- 4 - 兼容MYSQL
通常项目上,此参数设置为2,可以更好的适配基于ORACLE开发的产品代码。
【例子】
达梦数据库默认NULL 与空值是不等价的,NULL就是NULL,空值就是空值。某个功能查询需要同时满足它们,需要这样写:
|
|
ORACLE中默认NULL 和空值是等价的,同时满足只需要:
|
|
修改COMPATIBLE_MODE参数为2即可跟在ORACLE上的查询写法一致。
2)PK_WITH_CLUSTER
该参数默认为1
该参数与建表时的主键索引有关,达梦数据库在创建表时,如果创建主键,则默认主键是聚簇索引键。如果没有主键,则默认rowid 作为聚簇索引键
【例子】
当在达梦数据建表时,同时出现主键、字段为大字段CLOB类型的时候,就会报错:
|
|
此时,修改参数PK_WITH_CLUSTER=0 ,再创建有主键、字段为CLOB类型的表,就可以创建成功。
【关于聚簇索引】
表(列存储表和堆表除外)都是使用 B+树(以下简称 B 树)索引结构管理的,每一个普通表都有一个聚集索引,数据通过聚集索引键排序,根据聚集索引键可以快速查询任何记录。(即表是一个索引,这个索引名称叫聚集索引,可以理解为创建一个表后,将所有字段放在一起建立一个复合索引,只不过这个不需要我们来创建,系统自动给我们维护了一个)
当建表语句未指定聚集索引键,DM 的默认聚集索引键是 ROWID,即记录默认以 ROWID 在页面中排序。ROWID 是 B 树为记录生成的逻辑递增序号,表上不同记录的 ROWID 是不一样的,并且最新插入的记录 ROWID 最大。很多情况下,以 ROWID 建的默认聚集索引并不能提高查询速度,因为实际情况下很少人根据 ROWID 来查找数据。
原文链接: https://blog.csdn.net/sinat_32856657/article/details/125410328
3)CALS_AS_DECIMAL
该参数是控制 整数除法运算是否舍弃小数。
在达梦数据库中,整数相除或者使用ROUND函数,结果如果有小数位,会被直接舍弃,返回整数。
比如
|
|
可修改CALC_AS_DECIMAL=1 让运算不舍弃小数位
关于参数修改方式
第一种:通过dm.ini 修改参数
第二种:在达梦SQL窗口中,执行:
|
|
确认数据库用户权限
产品需要的用户大部分情况下是使用了DBA角色的权限,但是在项目实施时(特别是在生产环境中),会有部分客户认为产品上 DBA 权限不合理,也会有部分客户授权 DBA 是需要走流程申请。
所以这一点在前期就需要跟客户确认,用户权限能否授予DBA权限。
|
|
甚至有的客户(我遇到的一个),认为ANY权限也是有大隐患的,需要针对到具体表名的权限。
|
|
这种情况就没办法了,很麻烦,一个成熟且功能复杂的产品,可能标准版初始的表就有上千张(还不包括后续的开发新的功能表),存储过程、自定义函数等等也有上千个。每个存储过程用到的表都不一样,要一一梳理哪些用户select,哪个用户要delete等等,后期就需要额外的花时间去进行梳理。(虽然更安全、合规,但是麻烦的是我~吐槽一下)
达梦权限说明
通常我们在部署时,JDBC 中的连接,我们使用 WOLF WOLFDATA 用户去连接,或者使用 WOLF 去配置两个 JDBC 连接,指向 WOLF WOLFDATA 模式(达梦中 schema 的概念,可以把它当成 oracle 的实例概念)。
使用了 WOLF 用户去配置 JDBC 连接,那么此时,在系统进行日常操作的时候,在数据库中就是基于 WOLF 用户对对各个对象(TABLE \ SP \ FUNCTION \ VIEW \ TYPE \ PACKAGE 等)进行增删改查操作。
通常情况下,框架提供的默认权限脚本权限多含 DBA 或者 ANY 权限,但是在生产环境上其实是不被允许的。在用户具备 DBA \ DROP ANY OBJECTS 的情况,能做的事情比较多,包括了对表空间(数据文件)的更改、跨用户删除表 等危险操作。
因此在权限上,有的客户会要求梳理到具体的表需要什么权限。
|
|
|
|
前期将这些沟通好,等客户给服务器的相关信息,就可以开始着手准备实施部署产品了。